Paper Link: https://arxiv.org/abs/1912.10205
Decoupled Attention Network (DAN)
What is the difference?
 |
 |
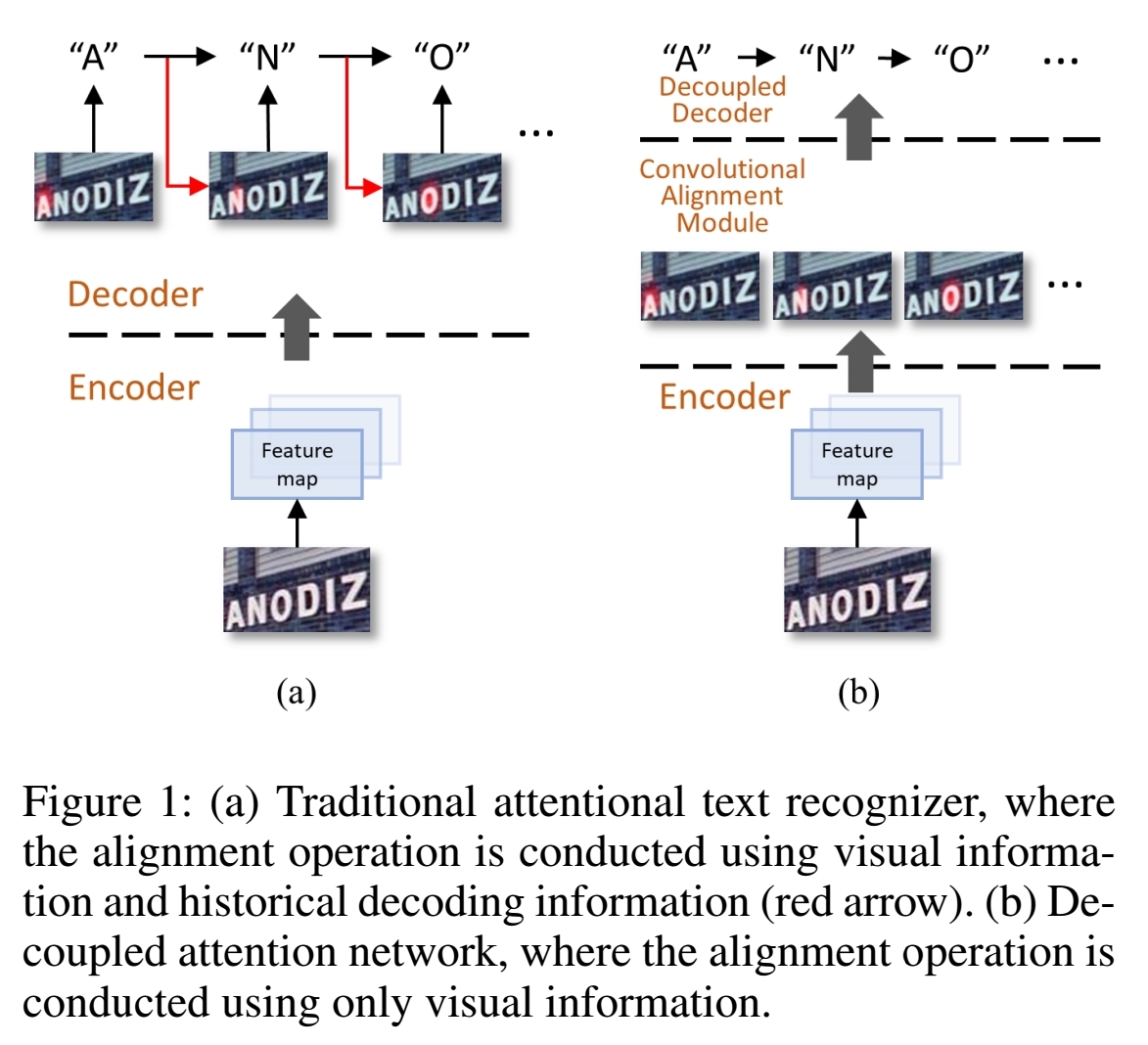
In traditional attention mechanism, alignment is coupled with decoding. They conduct alignment operation using visual information and historical decoding information.
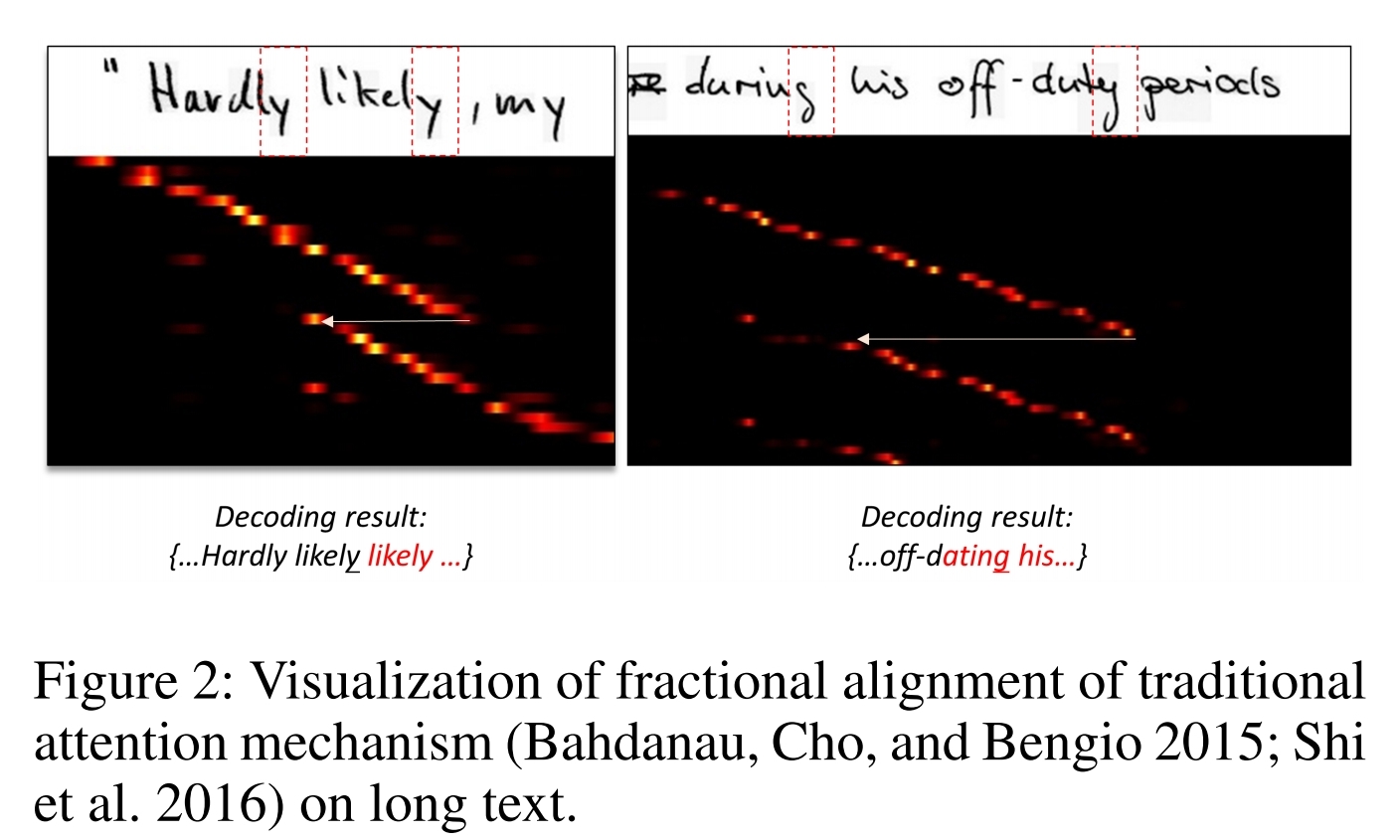
Traditional attention mechanism often have alignment problems. Alignment can be affected by “past historical decoding information”. This can confuse alignment. As shown in figure 2, matching operation is confused by “ly” and “ing”. Also, traditional attentions struggle with aligning a long sequence.
To solve these problems, authors separate into “alignment module” which conduct alignment operations only with visual information and “text decoder” which conduct recognition only using visual information and aligned attention map together.
Contributions
- CAM (Conditional Alignment Module): CAM is replacing traditional attention alignment module. Only watching visual information of CAM eliminates misalignment of decoding errors.
- DAN (Decoupled Attention Network): DAN is a effective, flexible (can beeasily switched to adapt to different scenarios) and robust (more robust to text length variation and subtle disturbances) SOTA attentional text recognizer.