Basic Deep Learning Concepts
Hard concepts are Bolded
- Supervised Learning / Unsupervised Learning / semi-supervised, weakly-supervised
- weight initialization
- learning rate decay
- dropout
- forward propagation(inference) / backward propagation
Activation
- What is activation layer and why use it
- ReLU, Leaky ReLU
- softmax
- sigmoid
- Difference of softmax and sigmoid
Loss
- What is loss and why use it
- L1 Loss, L2 Loss(=MSE Loss)
- binary cross entropy
- cross entropy
- Difference of binary cross entropy and cross entropy
- Why use binary cross entropy with sigmoid, cross entropy with softmax
Networks
- CNN (Convolution Neural Networks)
- deconvolution layer (transpose convolution)
- dilated convolution
- RNN (Recurrent Neural Networks)
- residual connection
- U-net
Train with less data
- data augmentation
- transfer learning
- semi-supervised, weakly-supervised
- domain adaptation
Normalization
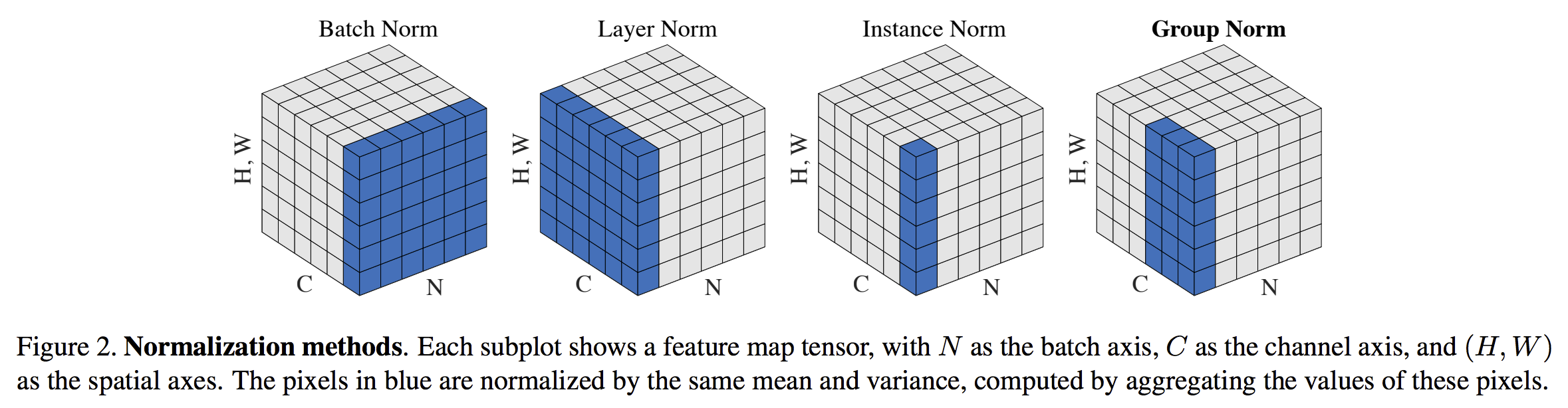
- batch normalization
- Layer Norm
- Instance Norm
- Group Norm
Sites
- Up-sampling with Transposed Convolution (en)
- An Introduction to different Types of Convolutions in Deep Learning (en)
- korean translate: https://zzsza.github.io/data/2018/02/23/introduction-convolution/ (kor)
- A guide to convolution arithmetic for deeplearning (en)
- Attention? Attention! (en)
- Billion-scale semi-supervised learning for state-of-the-art image and video classification
- N-Dimensional Space (kor)
- key, query, values in attention (en)
- Neural Networks, Manifolds, and Topology (en)
- blog post about Optimizer (kor)
- d2l textbook (en)
- d2l korean textbook (kor)
- distill.pub (en)
- colah blog (en)
Lectures
cs231n
- http://cs231n.stanford.edu/ (en)
- https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv (en)
- https://cs231n.github.io/ (en)
- http://aikorea.org/cs231n/ (kor)