Paper Link: https://openreview.net/forum?id=Bygh9j09KX
Abstract

ImageNet-trained CNNs are strongly biased towards recognising textures rather than shapes, which is in stark contrast to human behavioural evidence and reveals fundamentally different classification strategies.Authors then demonstrate that the same standard architecture (ResNet-50) that learns a texture-based representation on ImageNet is able to learn a shape-based representation instead when trained on ‘Stylized-ImageNet’, a stylized version of ImageNet.
→ ImageNet-trained CNNs are concentrate on texture and this could be solved by Stylized-ImageNet.
Concentrating on shape rather than texture is much better fit for human behavioral performance and has benefits such as improved object detection performance and robustness toward a wide range of image distortions.
Introduction
In this work authors aim to shed light on this debate with a number of carefully designed yet relatively straightforward experiments.
shape hypothesis (Context)
- One widely accepted intuition is that CNNs combine low-level features (e.g. edges) to increasingly complex shapes (such as wheels, car windows) until the object (e.g. car) can be readily classified.
- explanation that CNNs see overall context which needs to see larger than concentrate on texture
- CNNs are currently the most predictive models for human ventral stream object recognition (e.g. Cadieu et al., 2014; Yamins et al., 2014); and it is well-known that object shape is the single most important cue for human object recognition (Landau et al., 1988), much more than other cues like size or texture (which may explain the ease at which humans recognize line drawings or millennia-old cave paintings).
texture hypothesis (Locality)
- Contrast to shape hypothesis, there are finding points to the important role of object textures for CNN object recognition.
- CNNs can still classify texturised images perfectly well, even if the global shape structure is completely destroyed
- two studies suggest that local information such as textures may actually be sufficient to “solve” ImageNet object recognition:
- Gatys et al. (2015) discovered that a linear classifier on top of a CNN’s texture representation (Gram matrix) achieves hardly any classification performance loss compared to original network performance.
- Brendel & Bethge (2019) demonstrated that CNNs with explicitly constrained receptive field sizes throughout all layers are able to reach surprisingly high accuracies on ImageNet, even though this effectively limits a model to recognizing small local patches rather than integrating object parts for shape recognition.
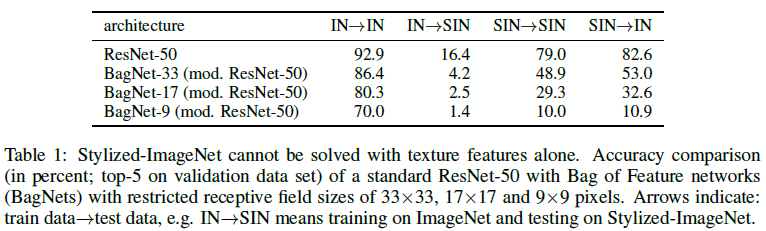
→ it seems that local textures indeed provide sufficient information about object classes—ImageNet object recognition could, in principle, be achieved through texture recognition alone. object textures are more important than global object shapes for CNN object recognition.
Experiments
Utilizing style transfer (Gatys et al., 2016), authors created images with a texture-shape cue conflict such as Figure 1c. Authors perform nine comprehensive and careful psychophysical experiments comparing humans against CNNs on exactly the same images, totaling 48,560 psychophysical trials across 97 observers.
→ These experiments provide behavioral evidence in favor of the texture hypothesis: A cat with an elephant texture is an elephant to CNNs, and still a cat to humans.
Contributions
Beyond quantifying existing biases, authors subsequently present results for our two other main contributions: changing biases, and discovering emergent benefits of changed biases. They show that the texture bias in standard CNNs can be overcome and changed towards a shape bias if trained on a suitable dataset. Networks with a higher shape bias are more robust and reach higher performance on classification and object recognition tasks.
Methods
Models are ImageNet-pretrained networks.
Variable definitions
- silhouette: bounding contour of an object in 2D (i.e., the outline of object segmentation).
- object shape: a definition that is broader than just the silhouette of an object: we refer to the set of contours that describe the 3D form of an object, i.e. including those contours that are not part of the silhouette.
- texture: an image (region) with spatially stationary statistics. Note that on a very local level, textures(according to this definition) can have non-stationary elements (such as a local shape): e.g. a single bottle clearly has non-stationary statistics, but many bottles next to each other are perceived as a texture: “things” become “stuff”. For an example of a “bottle texture” see Figure 7.
5 simple recognition task
It is important to note that the Authors only selected object and texture images that authors are correctly classified by all four networks.
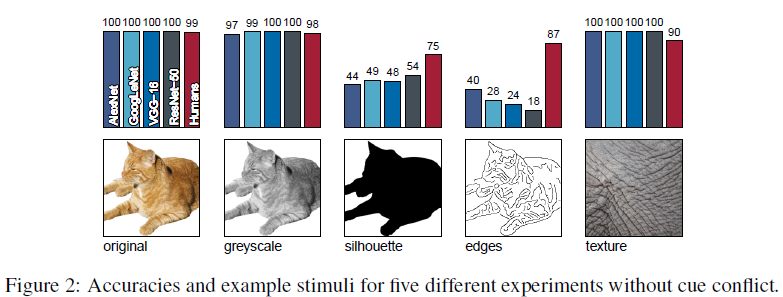
- Original: 160 natural colour images of objects (10 per category) with white background.
- Greyscale: Images from Original data set converted to greyscale
- Silhouette: Images from Original data set converted to silhouette images
- Edges: Images from Original data set converted to an edge-based representation
- Texture: 48 natural color images of textures (3 per category). Typically the textures consist of full-width patches of an animal (e.g. skin or fur) or, in particular for man-made objects, of images with many repetitions of the same objects (e.g. many bottles next to each other)
Cue Conflict task
Images generated using iterative style transfer (Gatys et al., 2016) between an image of the Texture data set (as style) and an image from the original data set (as content). The authors generated a total of 1280 cue conflict images (80 per category), which allows for presentation to human observers within a single experimental session.

Stylized-ImageNet (SIN)

Starting from ImageNet authors constructed a new data set (termed Stylized-ImageNet or SIN) by stripping every single image of its original texture and replacing it with the style of a randomly selected painting through AdaIN style transfer (Huang & Belongie, 2017) (see examples in Figure 3) with a stylization coefficient of \(\alpha\) = 1.0.
Styled-ImageNet is produced in different way with Cue Conflict task
Results
Texture vs Shape bias in humans and ImageNet-trained CNNs
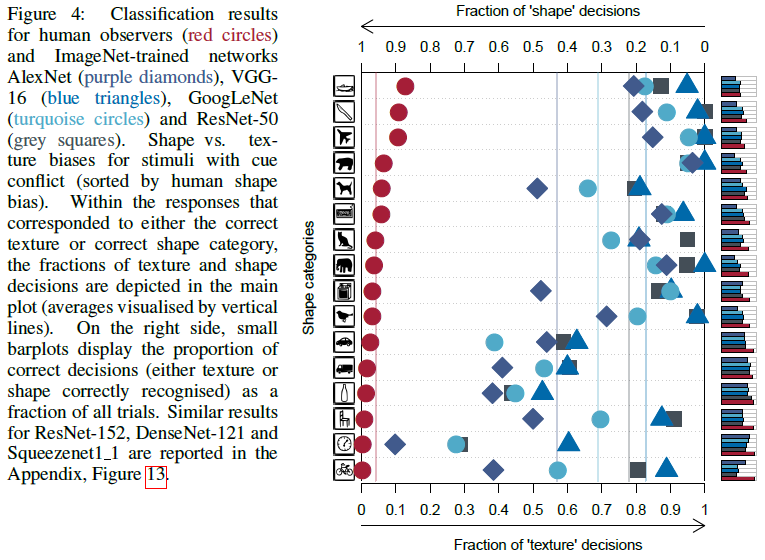
One confound in 5 simple recognition tasks is that CNNs tend not to cope well with domain shifts, i.e. the large change in image statistics from natural images (on which the networks have been trained) to sketches (which the networks have never seen before).
ImageNet can be solved to high accuracy using only local information. In other words, it might simply suffice to integrate evidence from many local texture features rather than going through the process of integrating and classifying global shapes.
Overcoming the texture bias of CNNs
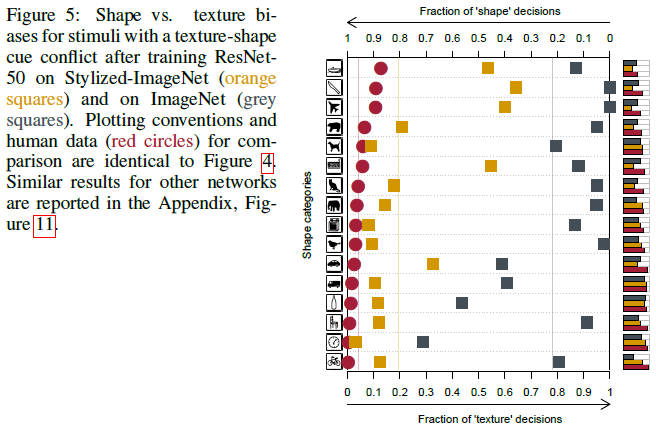
The SIN-trained ResNet-50 shows a much stronger shape bias in our cue conflict experiment (Figure 5), which increases from 22% for a IN-trained model to 81%. In many categories, the shape bias is almost as strong as for humans.
Does the increased shape bias, and thus the shifted representations, also affect the performance or robustness of CNNs? In addition to the IN- and SIN-trained ResNet-50 architecture authors here additionally analyse two joint training schemes:
- Training jointly on SIN and IN.
- Training jointly on SIN and IN with fine-tuning on IN. We refer to this model as Shape-ResNet.
Authors compared these models with a vanilla ResNet-50 on these three experiments:
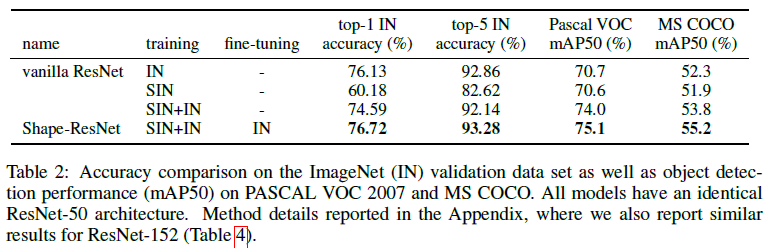
- Classification performance: Shape-ResNet surpasses the vanilla ResNet as reported in Table 2.This indicates that SIN may be a useful data augmentation on ImageNet that can improve model performance without any architectural changes.
- Transfer learning: The authors tested the representations of each model as backbone features for Faster R-CNN (Ren et al., 2017) on Pascal VOC 2007 and MS COCO. Incorporating SIN in the training data substantially improves object detection performance as shown in Table 2.
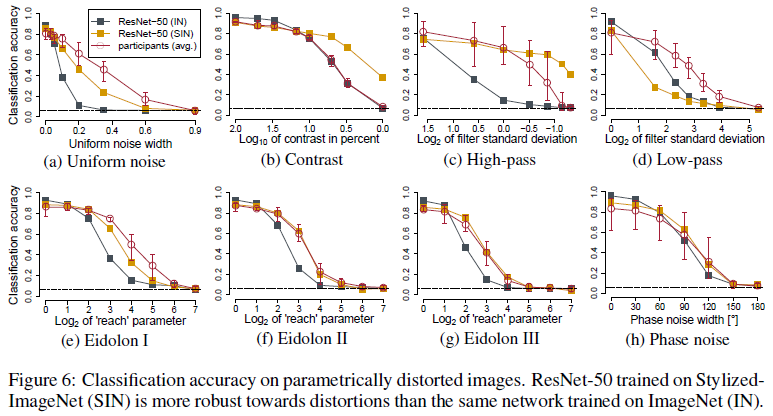
- Robustness against distortions: Authors tested how model accuracies degrade if images are distorted by uniform or phase noise, contrast changes, high- and low-pass filtering, or eidolon perturbations. The results of this comparison are visualized in Figure 6. While lacking a few percent accuracies on undistorted images, the SIN-trained network outperforms the IN-trained CNN on almost all image manipulations.
Opinion
The robustness just could be from data augmentation?