Paper arxiv link: Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
Efficient Sub-Pixel Convolutional neural Network (ESPCN)
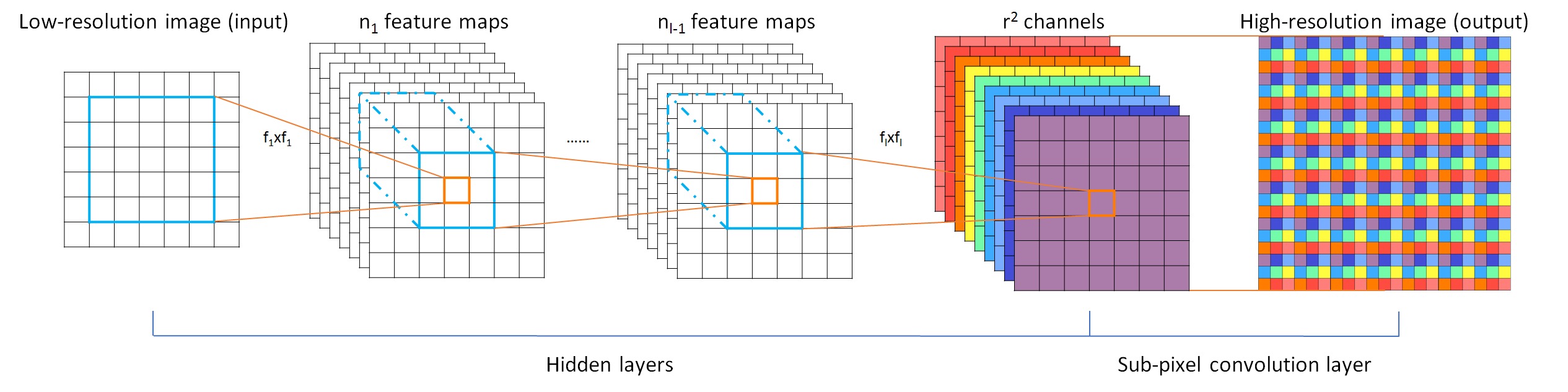
Figure 1. The proposed efficient sub-pixel convolutional neural network (ESPCN), with two convolution layers for feature maps extraction, and a sub-pixel convolution layer that aggregates the feature maps from LR space and builds the SR image in a single step.
Contrast to previous works
- super-resolve only at the end of the network (efficient sub-pixel convolution layer) → Eliminate the need to perform super-resolve in high resolution
Efficient sub-pixel convolution layer
- Last layer of ESPCN
- Rearrange tensor of \(H \times W \times C \cdot r^2\) to \(rH \times rW \times C\) tensor like Figure 1.
- Implemented at TensorFlow as depth to space and PyTorch as PixelShuffle
Advantages
- Upscaling at the last layer.
- Network operations like feature extracting are done at low resolution space. This means that this network needs less computational resource than operating network at high resolution.
- Learnable \(n\) upscaling filters
- Network learn \(n\) upscaling filters for feature maps at last layer rather than one upscaling filter for input image.
- This layer is not explicit interpolation filter, so network can implicitly learn processing necessary for super resolution.
→ Network can learn better and more complex low resolution to high resolution mapping than single fixed filter upscaling at first layer.